
Speaking to the Web with the Web Speech API

What if you could interact with the web without using a keyboard, mouse or touch? Another way to interact with the web is possible by using your voice. The Web Speech API allows you to interact with a website by talking and receiving audio feedback from the website. This new interaction method can allow users to cook while simultaneously looking for recipes and receiving instructions from a website.
The Web Speech API is composed of two parts: speech recognition and speech synthesis. Speech recognition is the browser’s ability to recognize what the user said. Developers can implement methods to interpret what the user said and associate with a work flow for the user to interact with the site. Speech synthesis is the browser’s ability to provide audio feedback. Developers can use speech synthesis to guide the user and relay information back to the user.
Web Speech API Demos
I built a simple Samsung shop website to demonstrate the Web Speech API. The demo listens for keywords that I defined to execute specific commands. The commands I implemented are:
Select (name of item on page): “clicks” on the item, which allows you to buy or add to cart
- example: “Select Samsung Galaxy S7”
Add: there are two cases, where the item will be placed in the cart
i. Add (name of item on page): “clicks” on the item and then “clicks” the “add to cart” button
example: “Add Samsung Galaxy S7”
ii. Add (to cart): Adds item to cart after the item is selected first (can be used with the Select command or after manually clicking on item)
example: “Add to cart”
Buy: there are two cases to this command, where both buys an item, which will trigger the Payment Request API payment sheet or redirect to the shopping cart page.
i. Buy (name of item on page): “clicks” on the item and then “clicks” the “buy now” button
- example: “Buy Samsung Galaxy S7”
ii. Buy (now): “clicks” the “buy now” button. This only works when an item is selected first
- example: “Buy now”
Go to cart: “clicks” the cart icon and redirects to the shopping cart page
- example: “Go to cart”
Checkout: “clicks” the checkout button on the shopping cart page (only works on shopping cart page)
- example: “checkout”
Back: goes back to previous page in your history
- example: “back”
Remove (name of item on page): removes an item from shopping cart page (only works in shopping cart page)
- example: “Remove Samsung Galaxy S7”
This demo can be found here. (The demo also uses the Web Payment API, which I will discuss in a future post.)
My colleague Diego also created a WebVR demo, Word Drop, using the Web Speech API. You can press the microphone button and speak. This will mix geometry, physics and text A-Frame components making all the recognized ‘matches’ “rain” down on your screen! Find the code here.

Web Speech API in WebVR (Word Drop)
Now I will discuss the Web Speech API methods I used.
Speech Recognition
The first step is to make sure the browser supports the Web Speech API.
if(‘webkitSpeechRecognition’ in window ){ }
Then, you can create a speech recognition object.
let speech = new webkitSpeechRecognition();
You can create a speech recognition list to be understood by the speech recognition object.
// The list of words to be recognized for specific actions
let words = [‘words’, ‘you’, ‘want’, ‘to’, ‘recognize’, ‘here’];
let grammar = ‘#JSGF V1.0; grammar actions; public
let speechRecognitionList = new webkitSpeechGrammarList();
speechRecognitionList.addFromString(grammar, 1);
speech.grammars = speechRecognitionList;
You can set the language by setting the ‘lang’ property with the correct BCP 47 language tag:
speech.lang = “en-US”;
The speech recognition object can also return each recognition or return a single recognition. Setting continuous to true returns just one recognition and setting continuous to false returns results for all recognition.
speech.continuous = true;
The interimResults property is not necessary, but very useful to see how the speech recognition object generates the final result. By setting the property to true, low confident results are returned.
speech.interimResults = true;
The maxAlternatives returns a specified number of similar results during the interpretation. Default value is 1 to return a single result.
speech.maxAlternatives = 1;
Speech recognition also has event listeners to handle different scenarios that may happen during user interaction. A few I used are:
- onstart: This event is fired when the start() method is called.
- onend: This event is fired when the speech recognition object is no longer listening to user input.
- onresult: This event is fired when the speech recognition object finishes analyzing the voice input.
- onerror: This event is fired when something bad happens.
Speech Synthesis
To get started with speech synthesis:
let synthesis = window.speechSynthesis;
Then you can set up an utterance, which will convert text to speech.
let textToSpeech = new SpeechSynthesisUtterance(text);
You can also control how the text is read.
To get your speech synthesis object to output the result:
synthesis.speak(textToSpeech);
More Information on the Web Speech API
For more information on the Web Speech API, click here. The Web Speech requires the site to be loaded from a secure origin. Make sure your server uses HTTPS. HTTPS can be enforced on the web page as shown below:
if (location.protocol != ‘https:’) {
location.href = ‘https:’ + window.location.href.substring(window.location.protocol.length);
}
Also users have to opt-in for the web page to gain access to the microphone.
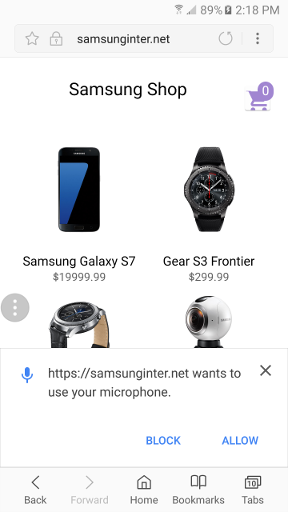
Permissions in Samsung Internet
For those who want to see other audio-related features on the web, check out Diego’s article on Web Audio.
Tagged in Web Development, JavaScript, Speech, Accessibility, Web
By Winston Chen on August 7, 2017.